先简单介绍一下 OpenClaw:它是一个开源、自托管的 AI Agent。你可以把它理解为“消息渠道”和“AI 执行能力”之间的统一中枢:一边连 Telegram、WhatsApp 等聊天软件,另一边连模型、工具、会话和记忆系统。
我给这个助手起名叫 Jeff,灵感来自电影《Finch》(2021,Tom Hanks 主演)里那个被训练来陪伴和协助人类的机器人。这个名字对我来说挺有象征意义:我希望它不是“回答机器”,而是一个能长期协作、持续进化的工作搭子。
对我来说,OpenClaw 最关键的不是“会聊天”,而是它能持续执行真实任务。
这段时间我做了一些配置,把它接进了我每天的工作流。在这篇文章里面简单和大家分享一下我使用 OpenClaw 的一些体会:
我为什么会开始用 OpenClaw
我对 AI 工具的要求很实际:
- 能执行命令,不只是给建议;
- 能记住上下文,不用每次重讲背景;
- 能定时做事,而不是我手动触发;
- 能把结果送达我,而不是让我自己翻日志。
OpenClaw 基本满足了这四点,所以我决定把它当“长期协作者”来用。
安装后我先做了哪些配置
我没有一上来就让它“写东西”,而是先做基础配置,让系统先稳定。这里面有一个我自己很满意的点:很多能力不是靠改配置文件硬啃出来的,而是通过连续对话一步步把 Jeff(我的 OpenClaw 助手)调教出来的。
一些配置通过和 OpenClaw 对话就可以完成,例如让 OpenClaw 支持“语音对话”这件事,我只是在聊天时问他如何可以支持语音对话,OpenClaw 就自己下载安装了 Python,fast-whisper,并编写了 voice2text 脚本,自己实现了语音对话。
我还让 OpenClaw 自己将创建了备份策略,将他的配置,memory 文件,数据库 和 Workspace 中的重要文件定时备份到我 GitHub 的私有 Repo 中,以在服务器出问题或者将来 需要迁移时可以快速恢复。
一些稍微复杂的配置,例如 Github MCP 的配置,Gmail 连接,Telegram 的配置则是我在 OpenClaw 的帮助下手动配置的,也没有花太多时间,一小时以内都搞定了。
我的实际使用案例
下面这些都是我们真实对话里已经做过的:
案例 A:快速验证用户的 Envoy / 网关配置
这是第一次让我对 OpenClaw 的能力发出 “哇” 惊叹的时刻。
当时社区有人给出一段 Istio 配置和故障现象时,我通过 Telegram 直接把这个配置和故障描述贴给了 Jeff 的对话框让其去验证,通过对 Jeff 的几个指令,Jeff 就帮我完成了整个过程,并且把结果反馈给了我。
果我自己去验证,需要一步步:
- 安装了 kind 集群
- 安装了 Istio Ambient + Envoy Gateway
- 按给定 YAML 部署 Waypoint / HTTPRoute / AuthorizationPolicy
- 验证 GET 请求是否被策略拦截
这些步骤非常繁琐,而把这个任务交个 Jeff,我全程不用关心,继续去处理自己的事情了。
案例 B:GitHub Standup 自动投递
我们组每天下午下班前要写一个简报,主要就是在 Slack 群里汇报一下自己当天的工作进展。而我一天的工作会在各种任务之中进行切换,在下班时花时间来回忆 自己当天到底做了哪些工作并编写这个汇报,对我而言,是一个很痛苦的事情,因为我比较烦这种程序性的汇报工作。于是我就让 Jeff 写了一个 Sikll, 通过 Github MCP 自动 获取我当天的所有 Github 活动,包括:
- PR(opened/closed/updated)
- Issues created
- Issues triaged(按评论时间校验)
- Reviewed PRs(approved/commented)
然后总结成一个简报,定时在晚上 6 点通过 Telegram 发送给我:
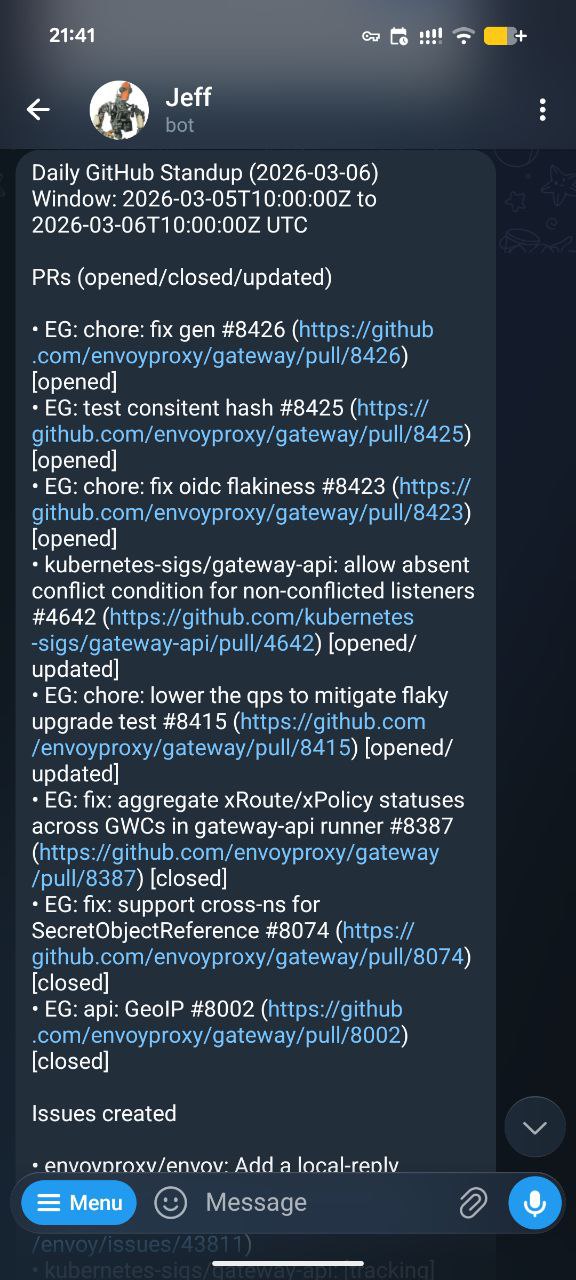
我直接拷贝到 Slack 群里即可。
案例 C:每日邮件总结
另一个我厌烦的事情就是检查邮箱,没有每天检查邮箱的习惯,有时候会错过一些重要的邮件消息。于是我给 Jeff 我的邮箱只读权限,让他每天在上午 9 点时给我发一条 新邮件的总结消息,将新邮件自动按照优先级进行排序,提醒我哪些邮件需要处理,哪些邮件是广告,可以直接忽略。
这样我每天上班前看一下 Jeff 的邮件总结消息就可以了,即不会错过重要的邮件消息,也不用一封封去查阅新邮件。
案例 D:内容生产与发布
这篇文章本身就是一个案例:我让 Jeff 根据我们的对话记录总结成一篇博客文章。
我只是给 Jeff 发送了几条语音指令,Jeff 就做了下面的事情:
- 从 Github 下载我的博客 Repo
- 分析我博客 Repo 中已有的 Markdown 文件的格式
- 根据我们之间的对话记录,生成一篇博客文章
- 将博客文章保存到我的博客 Repo 中
- 将博客文章推送到 Github,触发 Netlify 的自动部署
从我发出指令到博客文章上线,整个过程不到 5 分钟。
安全性和成本
安全性和成本可能是大家最关心的两件事。
我目前把 OpenClaw 放在云端 Ubuntu 主机上运行,和本地个人设备做了一层隔离,尽量降低敏感信息暴露风险。当前接入的外部能力也做了权限控制:
- Gmail:只读(用于收件摘要)
- GitHub:读写(用于仓库自动化)
这套权限设计的原则很简单:够用就好,最小权限优先。后面根据具体的使用情况和需求,再考虑接入更多的外部能力。
至于成本,Token 花费整体在可接受范围内,没有出现“失控烧钱”。模型侧我主要用 GPT-3.5-Codex,而且走的是我现有 ChatGPT Plus 订阅(每月 20 美元)额度。和我日常 Coding Agent 工作一起使用,目前配额仍然够用。因此没有为 OpenClaw 的单独开支。
当然这主要是我目前还没有使用 Jeff 来进行一些比较繁重的工作任务。我的日常编码工作还是主要使用的 Mac Codex App 和 Codex CLI。Jeff主要做一些事务性的重复工作,例如前面提到的生成每日工作报告。
我的结论
对我来说,OpenClaw 目前的主要价值目前在于下面几点:
- 一个 24 小时随时待命的私人秘书,可以通过手机上的聊天软件对其下发工作命令,随时处理我冒出的一些想法。
- 完成一些重复性的任务,如新邮件总结排序,生成每日工作报告,将这些琐碎事物从我的“大脑缓存”中清空,以让我可以专注到重要的任务上。
- 具备一定的自主性,可以自主完成一些工作任务,例如前面讲到的自己安装测试环境验证我给的一些 Envoy Gateway 配置。
目前我还在继续探索 OpenClaw 在工作和生活中的更多使用场景。你也在用 OpenClaw 吗?平时主要怎么用?欢迎在评论区留言交流,也可以加我微信一起探讨!